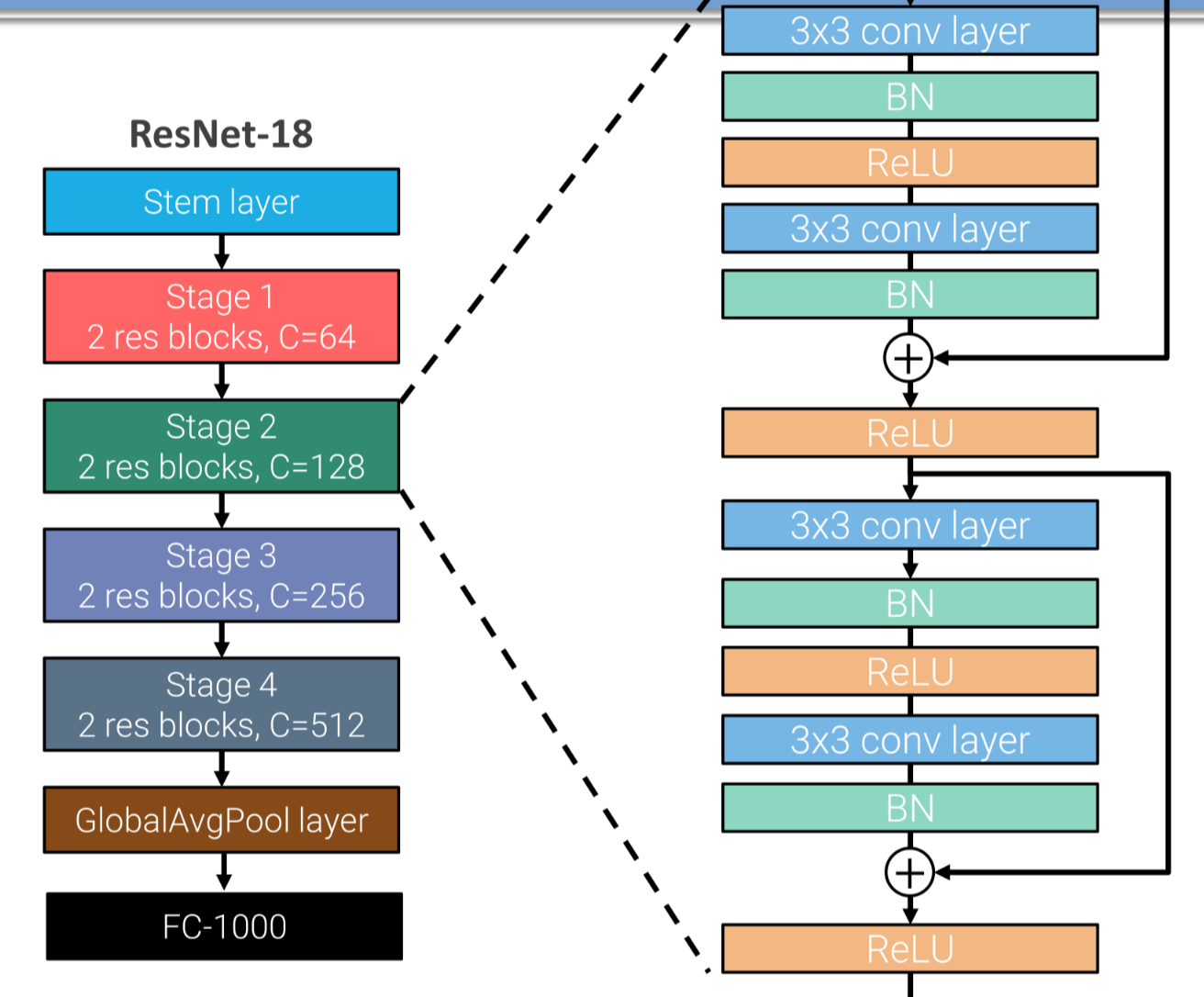
RESNET
CNN Inspired by VGG based on the concept of residual blocks, each stage of a resnet consists in a combination of residual blocks
RESIDUAL BLOCK STRUCTURE
each residual block (RB) contains 2 stages of convolution and ReLU non-linearity, the input of a RB block is summed to the output
The first RB in most stages halves the spatial resolution ( conv + max pool) and doubles the number of channels.
SUMMING INPUT AND OUTPUT
Input layer and output of a RB block are tensors of different shapes and cannot be added together
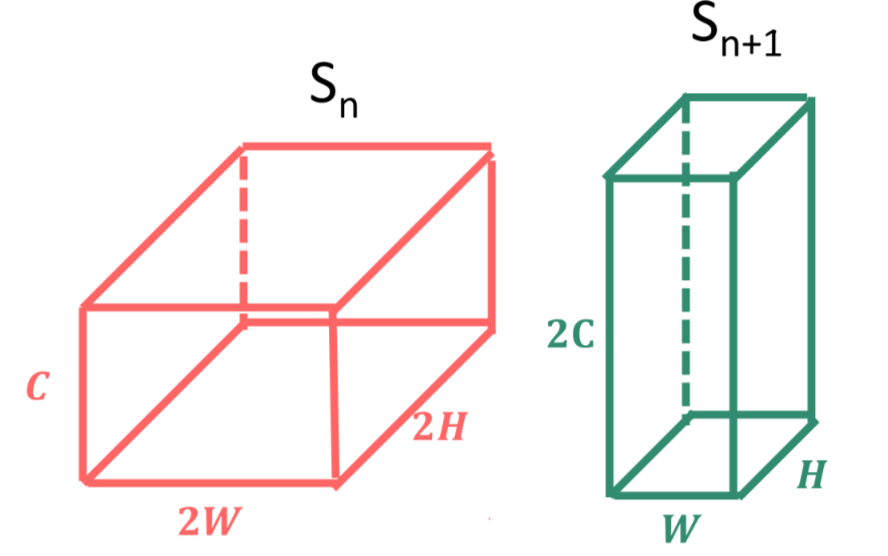
In order to address this situation a stage is added in the shortcut branch to increase the number of layers of the input
flowchart TD START:::hidden --> A A[1 x 1 convolution with S=2 and 2C] B[BN] C((+)) A --> B --> C classDef hidden display: none;
INCREASING DEPTH WITH BOTTLENECK RESIDUAL BLOCKS
In order to increase even further the depth of a CNN without increasing the computational cost bottleneck residual blocks are used which uses a pair of convolutional block to compress and decompress layers, this can cause information loss cause convolution and parameter learning are carried out in a compressed domain:
flowchart TD A[4C X H X W] B[\C X 4C X 1 X 1 conv + BN/] C[ReLU] D[3 X 3 conv + BN] E[ReLU] F[/4C X C X 1 X 1 conv + BN\] G((+)) H[ReLU] A --> B --> C --> D --> E --> F --> G --> H A --> G START:::hidden --> A H --> END:::hidden classDef hidden display: none;
AVOID THE INFORMATION LOSS
in order to overcome the limitation of bottleneck residual blocks mobilenet-v2 improved the model by using inverted blocks
flowchart TD A[Cin X H X W] B[/tCin X Cin X 1 X 1 conv + BN\] C[ReLU] D[tCin X Cin X 3 X 3 tCin conv + BN] E[ReLU] F[\Cout X tCin X 4C X 1 X 1 conv + BN/] G((+)) A --> B --> C --> D --> E --> F --> G A --> G START:::hidden --> A G --> END:::hidden classDef hidden display: none;
To improve performance the convolution step is performed as a depthwise convolutions, another improvement (proved by experimental evidence) is the absence of non linear blocks between residual blocks
RESNET TRAINING
In the training phase dropouts is not deployed because the use of batch normalization acts as regularizer
| HYPERPARAMETER | VALUE |
|---|---|
| Traiming Iterations | |
| Optimizer | SGD with |
| Learning Rate | , divided by 10 when the validation error plateaus |
| Weight Decay | |
| Momentum | |
| Data Augmentation, Normalization | Same as VGG |
| Initialization | He initilization |