ALEXNET
CNN that won the ILSVRC2012, powerfull network trained on 2 gpus
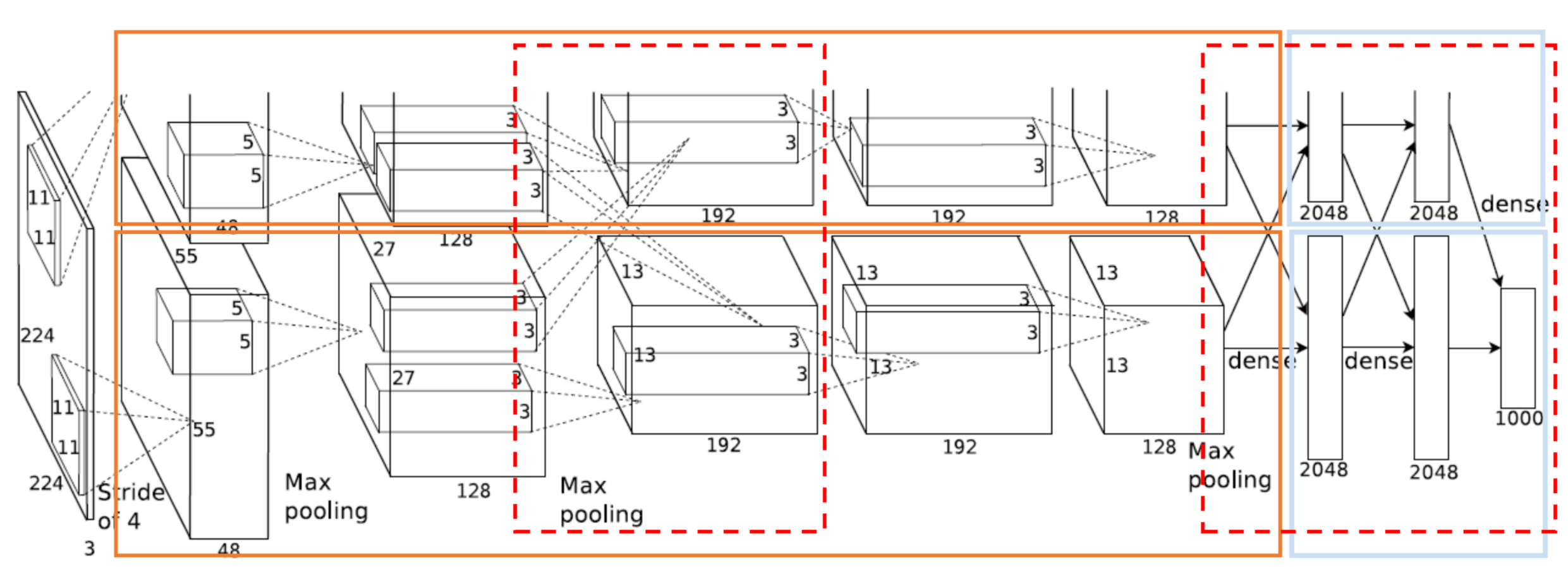
STRIDE PARAMETER
first conv layer has a stride of 4 to reduce the spatial dimension of input e reduce the computational costs, other layers as a stride of 1
POOLING LAYERS
the first 2 layers of the network are intervaled from a max pooling layer
IMPLEMENTATION OF NON LINEARITY
All layers (Conv and FC) deploy ReLU, non-linearities which yield faster training compared to saturating non-linearities
FULLY CONNECTED LAYERS SETUP
Last FC layer has 1000 units (as many as the ILSVRC classes), the penultimate FC layer is the feature/representation layer and has a cardinality of .
CHARACTERISTICS
Local Response Normalization (after conv1 and conv2): activations are normalized by the sum of those at the same spatial position in a few () adjacent channels (mimics lateral inhibition in real neurons).
in the FC6 FC7 layers Dropout is performed which means that at training time the output of each unit is set to zero with probability 0.5. This forces units to learn more robust features since none of them can rely on the presence of particular other ones.
TRAINING PHASE
Training was performed using random-cropping of patches (and their horizontal reflections) from the RGB input images and colour jittering (massive data augmentation).
At test time, averaging predictions (i.e. softmax) across 10 patches (central + 4 corner alongside their horizontal reflections).
| HYPERPARAMETER | VALUE |
|---|---|
| Optimizer | SGD with |
| Epochs | |
| Learning Rate | , divided 3 times by 10 when the validation error stopped to improve |
| Weight Decay | |
| Momentum | |
| Data Augmentation | Colour Jittering, Random Crop,Horizontal Flip |
| InitializationWeights | , Biases: 1 (conv2,conv4,conv5, fc6,fc7,fc8) or 0 (conv1,conv3) |
| Normalization | Centering (Subtraction of the Mean RGB colour in the training set) |