CREATING A CLASSIFIER
OBJECTIVE
design a function that takes image as input and responds with a label
A POSSIBLE TECHNIQUE, IMAGE FLATTENING
The idea is to scan linearly the image pixels:
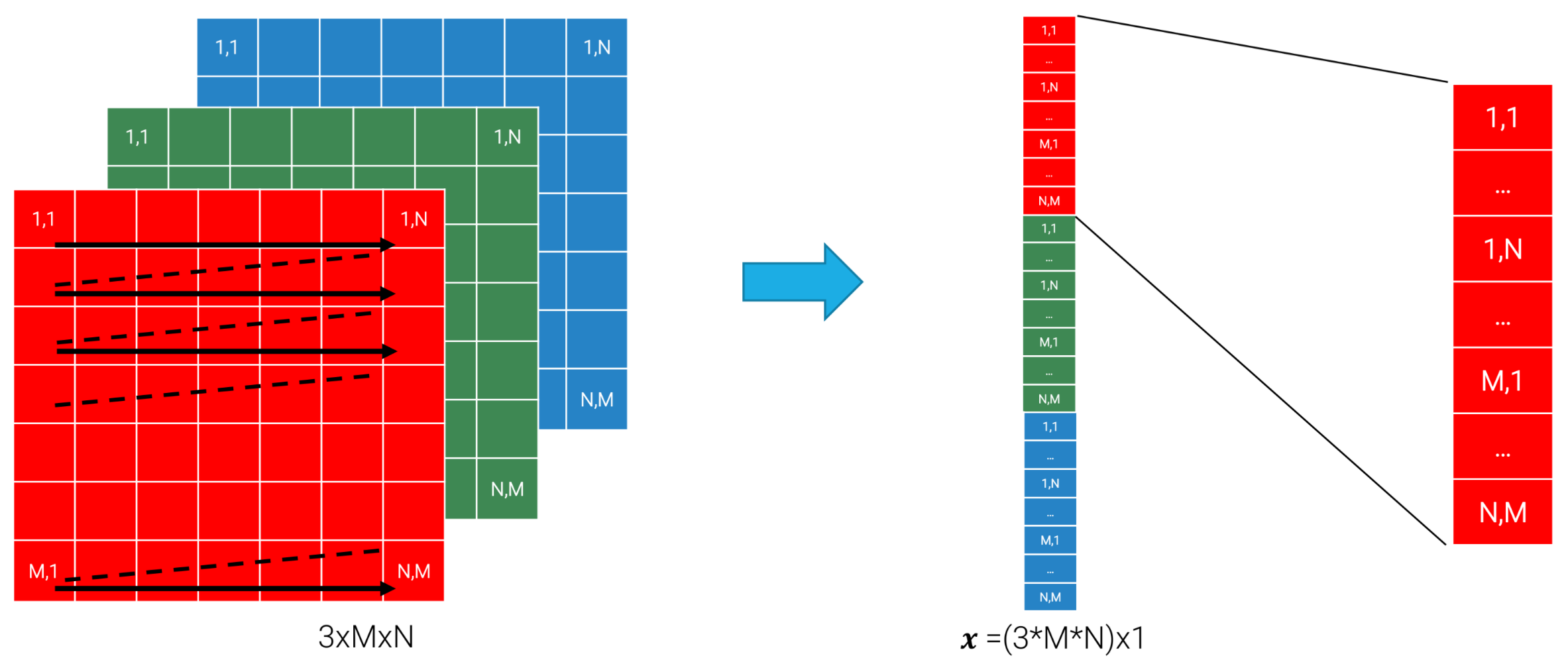
so the classifier becomes:
where is a linear vector of size as the input.
LIMITS OF IMAGE FLATTENING
This solution is not practical cause the label is a categorical and not numerical value so closer values do not imply that images are of similar classes
A better choice is to output scores for each label so
where is a matrix of size and scores is a vector of size
This type of linear classifier can be realize with the template matching approach Where templates are rows of the matrix
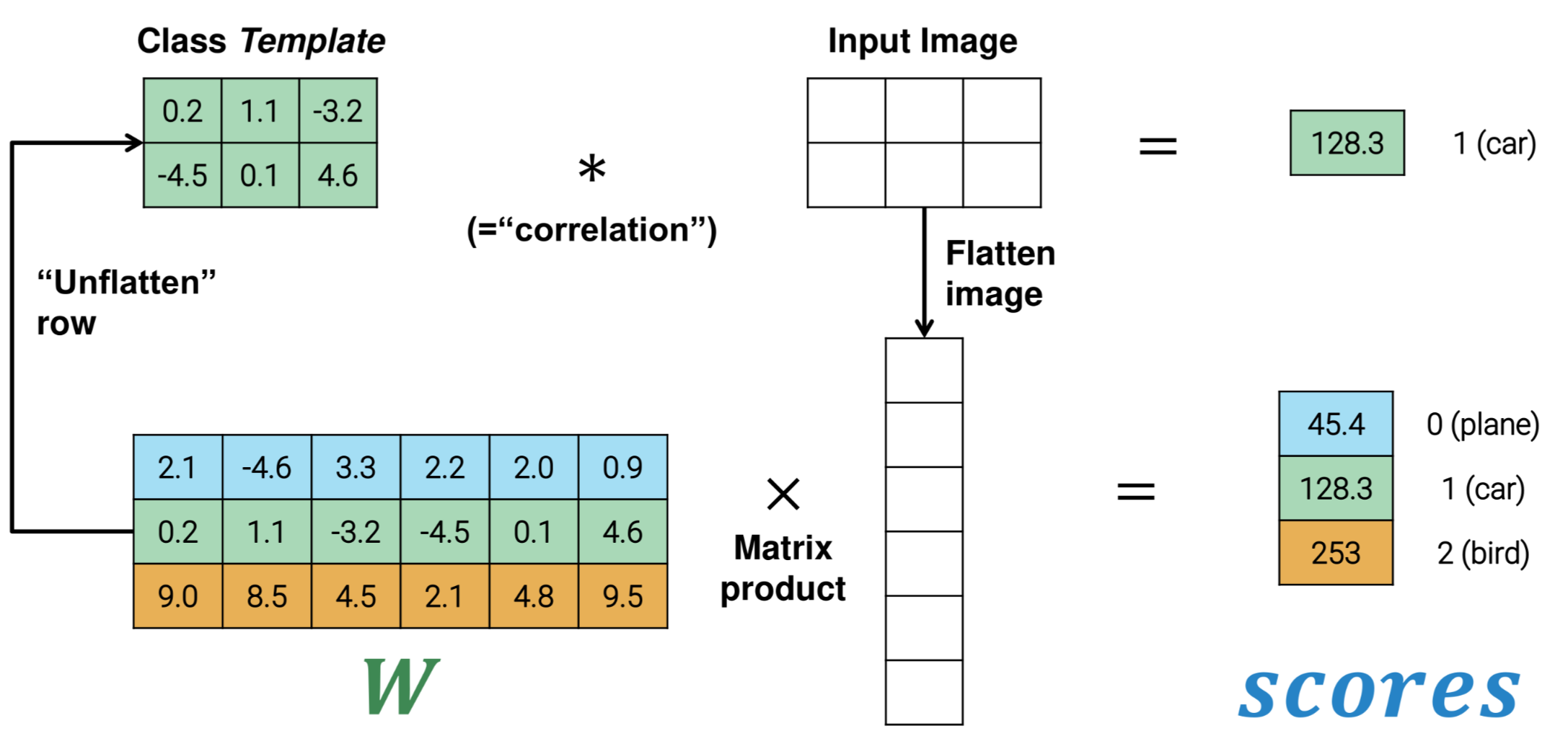
LOSS FUNCTION FOR A LINEAR CLASSIFIER
A common approach is to translate the scores in probabilities with the softmax function
the true label can be represented as a one hot encoded row of scores such as
The loss function must be a function that decrease as the probability given by the model becomes higher
So in the case of a linear classifier the function can be defined as
so the per sample loss is given by:
MINIMIZING THE LOSS FUNCTION
The loss function can be seen as a multivariate function with the variables being the parameters of the model so the problem becomes an optimization problem of the type
The most common approach to this problem is to compute the gradient of the loss function
and follow his direction (GRADIENT DESCENT)
GRADIENT DESCENT
- Randomly initialize
for epochs:
- Forward pass classify all training data to get the predictions and the loss function
- Backward pass compute the gradient
- Update parameters where is the learning rate hyper parameter
The learning rate can influence the convergence speed of the training procedure:
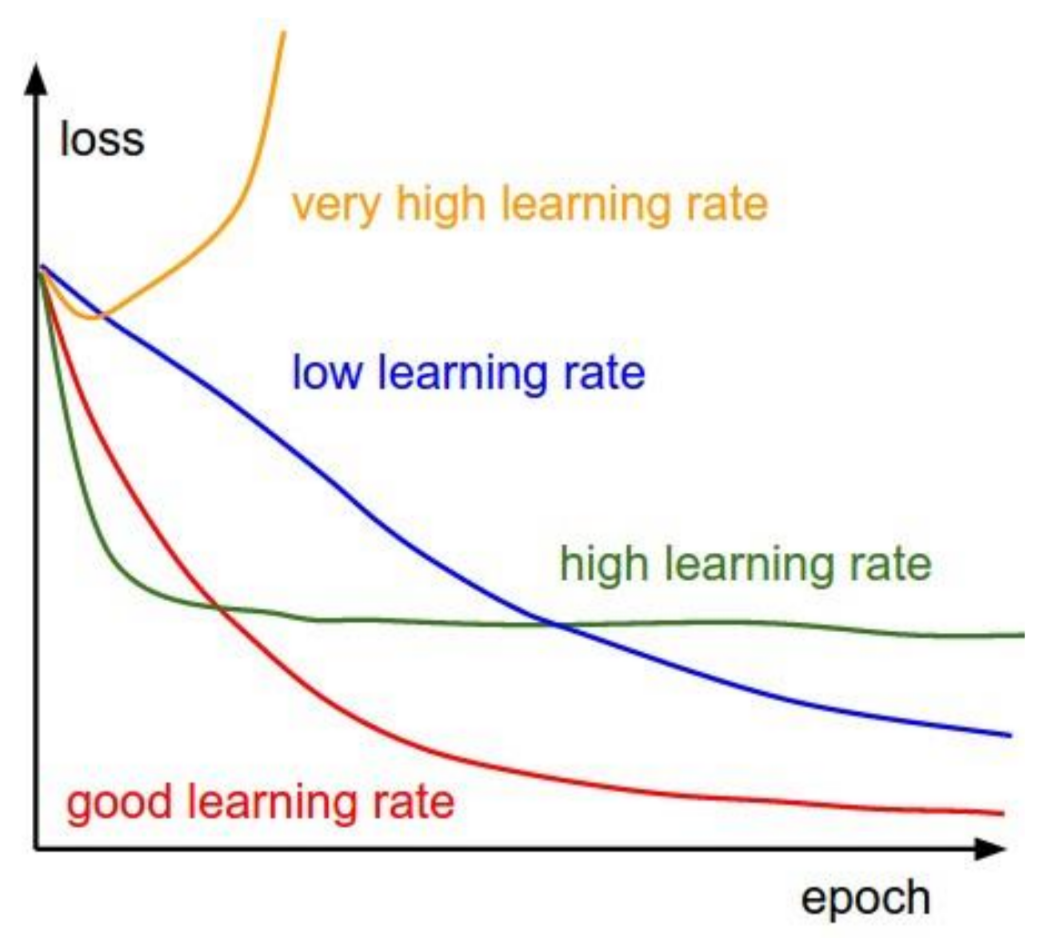
GRADIENT DESCENT LIMITS
Computing the gradient of the loss function on all the training data results in a computational infeasible task as the the loss function is the mean of the per-sample losses the gradient needs to be computed on ALL of the samples
STOCASTIC GRADIENT DESCENT
Instead of computing the gradient on the global loss function the parameter update is done for each sample, this method is more computationally efficient but is not robust to noise
BEST COMPROMISE
A good compromise can be to use mini data batches to compute the gradient choosing a batch of size ( is also an hyperparameter), the number of updates in each epoch (e.g. the number of batches ) can be computed as
In this case larger batches approximate better the gradient at the cost of memory occupation
IMPROVEMENT ON THE APPROXIMATIONS
In order to improve further the approximation a momentum parameter to the update phase can be deployed:
With this parameter the update becomes a mean of the previous ones smoothing the gradient
LIMITS OF A LINEAR CLASSIFIER
For a lot of application capture all the variability with one template is impossible, there is the need of something more meaningful than row pixels. There is the need to transform pixels in some form of feature
