RESOURCE MANAGEMENT PATTERNS
Patterns that are developed for managing data and resources in distributed environments
SESSION TOKEN
Pattern to handle session between server client communications, a token is sent to the client from the server with the following information
- session ID;
- security related data
- session state
- session TTL to avoid replay attacks
PROS
- session is preserved if mobile node changes the point of attachment to the network
- there is no overhead for the client in order to manage session
CONS
- server needs to manage the state of the session
CACHING
Simple concept, store acquired information from the server in order to reduce the number of communications needed to perform operation. When client needs a resource it ask the cache and request data to the server in case of a cache miss
EAGER ACQUISITION
All data needed by the application are fetched at startup to avoid network communication in the long run, improving performance at runtime. This increase startup times and can download data that are not used in the specific session
LAZY ACQUISITION
Data are fetched when the application requires them explicitly, reducing the data transfered over the network.
SYNCHRONIZATION
Pattern that allow to manage different data copies in different nodes, handling read write operations. Application delegates the read/write operations to a synchronization engine that handle the complexity of communicate to the other nodes detect and resolve conflicts
flowchart LR subgraph terminal A(synchronization engine) B[(data)] A <--> B end subgraph host C(synchronization engine) D[(data)] C <--> D end terminal <--> host
There are 2 possible models for synchronization
- process level multiple process access a resource and sequential interaction is imposed
- data level processes works on local copies of data and synchronization operations are triggered
flowchart LR subgraph Process_level C([Process A]) D([Process B]) E[LOCK] F[data item 1] C & D --> E --sync--> F end subgraph data-level subgraph system_A direction TB G([Process]) H[(data item 1)] G --> H end subgraph system_B direction TB I([Process]) J[(data item 1)] I --> J end subgraph main direction TB K[(data item 1)] I --> J end system_A & system_B --> K end Process_level ~~~ data-level
for data level synchronization some choices need to be made
- when to trigger sync operations manual versus automatic triggers
- how to manage sync operations
- optimistic multiple data copies are managed by the synchronization engine
- pessimistic approach only a single copy of the data is writable
SYNCHRONIZATION MECHANISMS
VERSIONING
Optimistic approach that relies on version numbers, that are associated to a resource, a version number is defined by the following characteristics
-
if version comes from changes are
-
two version number coming from the same version number are incompatible and needs a merge operation
-
update propagation;
-
changes detection;
-
reconciliation
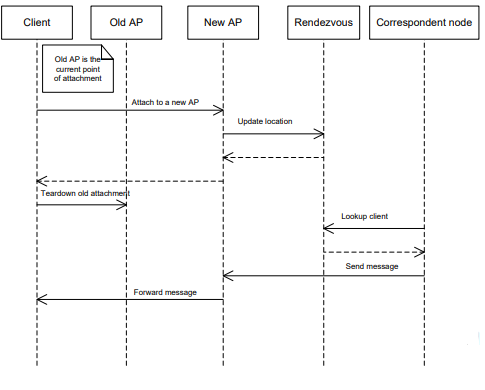
RENDEZVOUS
Pattern that allow nodes to synchronize data by meeting at randezvous points
flowchart LR A[client A] B[client B] C[rendezvous point] A --update data--> C B --lookup data--> C
WHAT IN REAL ENVIRONMENTS
in Real scenarios sincronization is used only between 2 nodes
- centralized
- tree structure nodes sync with the parent (more flexible solution using a cyclic connected graph)
STATE TRANSFER
Pattern that allows the infrastructure to manage handover situations exploiting RENDEZVOUS to update clients