COSTRUTTI LINGUISTICI E PROCESSI COMPUTAZIONALI
E importante comprendere la differenza tra ciò che esprime la sintassi con il processo computazionale che la macchina adotta, spesso infatti i due non coincidono.
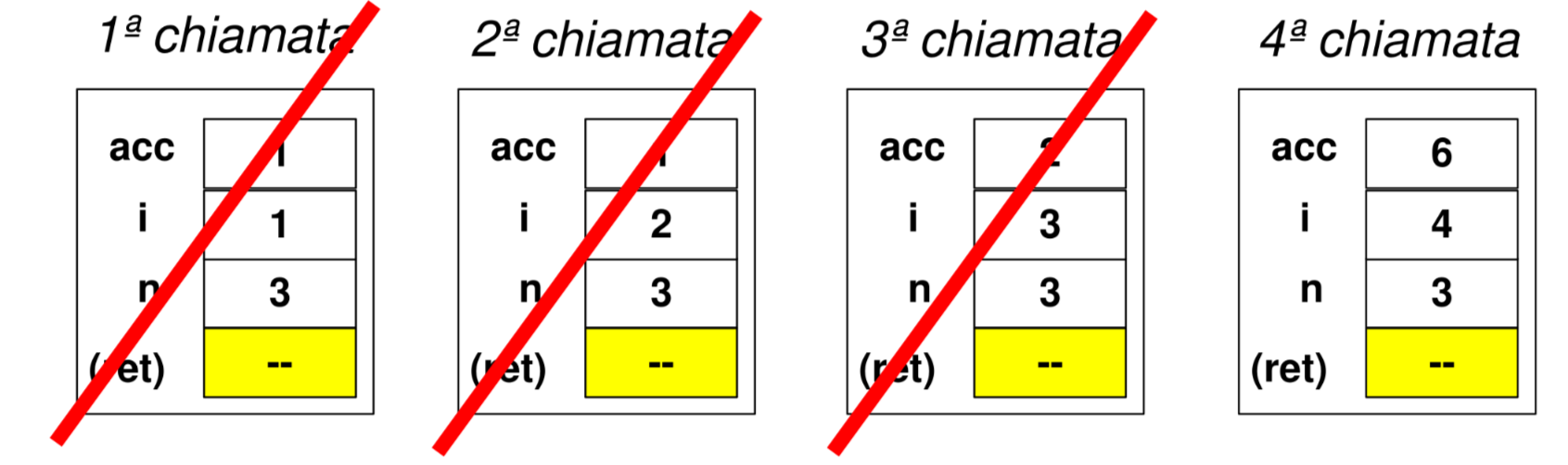
PROCESSO ITERATIVO VS PROCESSO RICORSIVO
Un esempio e il confronto fra processo ricorsivo e processo iterativo, per il processo iterativo infatti si può dire che:
- un accumulatore ad ogni chiamata si occupa di conservare il risultato parziale della -esima iterazione
- ad ogni iterazione l’accumulatore contiene -esimo risultato parziale
- il processo iterativo computa in avanti
mentre del processo ricorsivo si può dire che:
- non ci sono accumulatori
- ogni chiamata a funzione opera sul valore -esimo per sintetizzare il valore -esimo
- il processo ricorsivo opera all’indietro, ovvero il risultato viene accumulato quando la chiamata al caso base ritorna un valore
UN CASO DI DISCREPANZA TRA SINTASSI E PROCESSO, LA TAIL RECURSION
Tuttavia non e detto che una sintassi ricorsiva generi un processo ricorsivo, e il caso della TAIL RECURSION ovvero quando l’operazione di ricorsione e l’ultima cosa effettuata dalla funzione
function factIt(acc, i, n) {
return i>n ? acc : factIt(i*acc, i+1, n);
}
console.log(factIt(1,1,n))In questo caso il risultato parziale viene mantenuto in un accumulatore, che contiene il risultato parziale delle computazione.
Proprio per questo in molti linguaggi che non offrono costrutti per esprimere processi iterativi viene applicata la ottimizzazione della tail recursion (TRO)
TAIL RECURSION OPTIMIZATION
Processo attraverso il quale si riduce la memoria allocata da una tail recursion a un solo record di attivazione sovrascrivendo sempre lo stesso record in quanto i precedenti risultano ininfluenti
LINGUAGGI FUNZIONALI
Con l’aumentare della complessità dei sistemi software i linguaggi funzionali si sono fatti sempre più sentire, sia puri che miscelati a linguaggi tradizionali (blended), le feature che li caratterizzano sono
- distinzione variabili / valori (
varvsval) - costrutti come espressioni
- collezioni e oggetti immodificabili
- funzioni come first-class entities
- chiusure, lambda expressions
- lazy evaluation vs eager evaluation
- concisione, operatori come funzioni, null safety…
VALORI VS VARIABILI
Nei linguaggi funzionali non esiste il concetto di ‘variabile’ come elemento modificabile, ma solo il concetto di valore come elemento immodificabile, i linguaggi blended optano per una soluzione meno drastica supportando entrambi i paradigmi (keyword var,val)
COSTRUTTI COME ESPRESSIONI
Nei linguaggi tradizionali i costrutti (while,for,if,throw…) sono intesi come istruzioni (non restituiscono nessun valore) questo porta a ragionare in termini di sequenza di istruzioni e variabili d’appoggio riducendo cosi la leggibilità del programma
Nei linguaggi funzionali i costrutti vengono trattati esattamente come le espressioni (ritornano valori) evitando cosi questo problema
FUNZIONI COME FIRST CLASS ENTITIES
Nei linguaggi tradizionali le funzioni non sono altro che dei costrutti sintattici per racchiudere la logica del programma, i linguaggi funzionali invece le elevano a cittadini di prima classe ovvero:
- le funzioni possono essere dichiarate e usate al volo
- assegnate a variabili
- passate a un altra funzione
- possono essere ritornate da un altra funzione
CHIUSURA
Se il linguaggio supporta le funzioni come first class entities e le funzioni ammettono l’uso di variabili non definite localmente (variabili libere) allora possono essere implementate le chiusure
Si ha quando una funzione compie l’atto di ‘chiudere’ de parametri all’interno di un altra funzione, ciò e possibile solo in linguaggi che permettono le funzioni come first class entities:
function ff(f,x) {
return function(r){ return f(x)+r; }
}
// se poi si invoca ff si ha che f e x devono sopravvivere alla chiamata della funzione ff per far si di poter chiamare la funzione result
result=ff(Math.sin,10)
console.log(result(2))si ha quindi che le variabili di una chiusura devono mantenere il tempo di vita della chiusura stessa e non possono essere allocate sullo stack (verrebbero rimosse inseme al record di attivazione della funzione stessa)
VANTAGGI DELLE CHIUSURE
- Rappresentare e gestire uno stato privato e nascosto
- Creare una comunicazione nascosta
- Definire nuove strutture di controllo
- Riprogettare/semplificare API e framework di largo uso
CHIUSURA LESSICALE VS CHIUSURA DINAMICA
Se il linguaggio supporta le chiusure occorre definire quale sia l’ambiente della funzione stessa in cui questo deve operare:
- si ha una catena di ambienti definita dalla struttura del programma CATENA LESSICALE
- e una catena di ambienti generata a run-time data dalla sequenza di chiamate della funzione CATENA DINAMICA
La modalita in catena dinamica ha un grosso svantaggio, ovvero riduce la leggibilita del programma in quanto per comprendere il valore di una variabile libera e necessario ripercorrere mentalmente il runtime del programma e risalire dunque al valore della variabile stessa
var x = 20;
//funzione interna che fa uso di una variabile non definita internamente
function provaEnv(z) {
return z + x;
}
// funzione esterna che ridefinisce la variabile richiamata dalla funzione interna
function testEnv() {
var x = -1;
return provaEnv(18);
}
console.log(testEnv())
//....
// Javascript adotta la chiusura lessicale quindi l'output risultaIn caso di un approccio a chiusura dinamica l'output sarebbe stato determinato dalla ridefinizione di
xnella funzionetestEnvquindi17
La chiusura lessicale viene preferita dalla totalità dei linguaggi mainstream (la leggibilità del programma e un fattore chiave)
VALUTAZIONE DI FUNZIONI
Ogni linguaggio deve stabilire un modello per la valutazione delle funzioni che specifichi:
- quando valutare i parametri(subito/quando vengono usati dal chiamato)
- cosa si passa alla funzione (valore/indirizzo)
- come si attiva la funzione (sincrono/asincrono)
MODELLO APPLICATIVO
Il modello per la valutazione di funzioni piu utilizzato e quello applicativo
- parametri valutati subito
- passaggi di parametri per valore
- cedimento del controllo in maniera sincrona, il chiamante attende la conclusione del chiamato prima di procedere.
Il modello applicativo risulta semplice ed efficiente ma ha i suoi limiti
La valutazione immediata dei parametri puo portare a fallimenti non necessari in caso quei parametri non vengano utilizzati
var f = function(flag, x) {
return (flag<10) ? 5 : x;
}
var b = f(3,abort() ); // Errore!!
document.log("result =" + b);ALTERNATIVA, MODELLO CALL BY NAME
Per evitare questi limiti esiste una variante che computa i parametri nel momento in cui il chiamante ne fa utilizzo, in questo modo si possono superare i limiti della valutazione immediata, per realizzare tale modello i parametri passati al chiamato sono oggetti eseguibili
PERCHÉ IL MODELLO CALL BY NAME NON E UTILIZZATO
In molti linguaggi di programmazione non si adotta il modello call by name per una serie di motivi legati alle performance:
- i parametri sono oggetti eseguibili computazionalmente esosi (sicuramente piu di un valore secco o un indirizzo)
- e necessario un esecutore in grado di fare lazy evaluation
- la valutazione dei parametri avviene una volta per ogni utilizzo (ottimizzabile facendo caching della prima valutazione)
Oltre a questo molti casi di fallimento che tipicamente sono aritmetici possono essere gestiti per mezzo di NaN e infinity, ad esempio:
function explode(a,c){
if (c > 2){
return 0
}else{
return a
}
}
console.log(explode(10/0,1))Uno dei casi piu famosi di call by name sono le MACRO del C
#include <stdlib.h>
#include <stdio.h>
#define f(FLAG, X) (((FLAG)<10) ? 5 : (X))
int main(){
printf("%d",f( 3, 4/0)) ; // non dà errore!
}Che non danno errore in quanto l’operatore ternario non valuta mai il membro di destra
Tuttavia il modello call by name puo essere ricreato (in maniera sintatticamente esplicita) nei linguaggi che supportano le funzioni come first class entities, passando degli oggetti funzione come parametri
var f = function(flag, x) {
// diventano due funzioni
return (flag()<10) ? 5 : x(); // invoca le due funzioni
}
var b = f( function(){return 3}, function(){ abort()} );
console.log("result=" + b);Come si vede il passaggio di parametri ‘funzione’ rende il modello call by name esplicito all’utente, un passo ulteriore viene effettuato in scala che implementa il meccanismo di call by name per mezzo di una keyword
object CallByName {
//Qui => non è l'operatore di
//lambda expression, ma la
//keyword "by name"
def printTwo(cond: Boolean, a: =>Int, b: =>Int):Unit = {
if (cond) println("result = " + a );
else println("result = " + b );
}
def main(args: Array[String]) {
val x=5;
val y=4;
//Salto espressivo: non
//si vede più l'artificio!
printTwo(x>y, 3+1, 3/0 );
}
}